deepspeech2 应用代码,基于DeepSpeech2的语音识别应用代码解析与实现
浏览量: 次 发布日期:2025-03-03 21:12:19
DeepSpeech2是一个端到端的语音识别系统,基于深度学习技术。它使用循环神经网络(RNN)和卷积神经网络(CNN)来处理语音信号,并将其转换为文本。DeepSpeech2由百度硅谷AI实验室开发,是DeepSpeech的改进版本,旨在提高语音识别的准确性和效率。
DeepSpeech2应用代码通常包括以下几个部分:
1. 数据预处理:包括音频信号的读取、重采样、归一化等操作,以便于后续的模型训练。
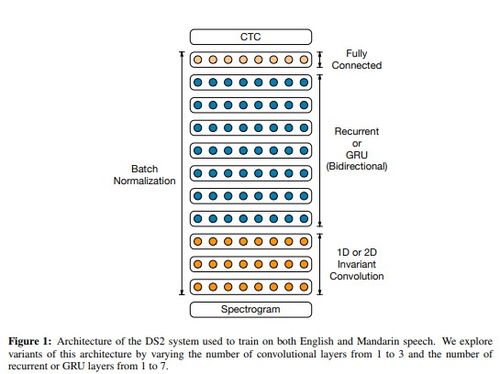
2. 模型构建:包括定义RNN和CNN的结构,以及相关的参数设置。常用的RNN结构包括LSTM和GRU,CNN结构则用于提取音频信号的局部特征。
3. 模型训练:使用预处理后的音频数据和对应的文本来训练模型。训练过程中,需要调整模型的参数,以最小化预测文本与真实文本之间的差异。
4. 模型评估:在训练完成后,使用测试集来评估模型的性能。常用的评估指标包括准确率、召回率和F1值等。
5. 模型部署:将训练好的模型部署到实际应用中,以便于实时或离线地处理语音信号并生成文本。
需要注意的是,DeepSpeech2应用代码的具体实现可能因不同的编程语言和框架而有所不同。例如,在Python中,可以使用TensorFlow或PyTorch等深度学习框架来实现DeepSpeech2模型。同时,为了提高模型的性能,可能还需要进行一些调优和优化操作,如超参数调整、数据增强等。你有没有想过,当你对着手机说话,它竟然能听懂你的话,还能把你的话变成文字呢?这就是神奇的深度语音识别技术,而其中的佼佼者就是DeepSpeech2。今天,就让我带你一起探索DeepSpeech2的奥秘,看看它是如何用代码将声音变成文字的!
一、初识DeepSpeech2:从原理到应用

DeepSpeech2,这个名字听起来是不是很高大上?它其实是一个基于深度学习的语音识别系统,由Mozilla开发。它利用神经网络模型处理音频数据,将其转化为可读的文字。是不是觉得有点复杂?别急,我来给你简单解释一下。
DeepSpeech2的核心是深度循环神经网络(RNN)和连接时序分类器(CTC)。RNN负责对语音序列进行建模,而CTC则负责将RNN预测的序列与实际语音文本对齐。简单来说,就是让计算机学会听懂你的话。
二、动手实践:DeepSpeech2应用代码解析
了解了DeepSpeech2的原理,接下来我们就来聊聊如何使用它。这里,我将以Python为例,带你一起看看DeepSpeech2的应用代码。
1. 安装依赖
首先,你需要安装一些依赖项,比如PyTorch、TensorFlow等。这里,我们以PyTorch为例,使用pip命令进行安装:
```bash
pip install torch torchvision torchaudio librosa soundfile
2. 数据准备
DeepSpeech2需要大量的语音数据来训练。你可以从网上下载一些公开的语音数据集,比如THCHS30。下载完成后,你需要对数据进行预处理,包括音频波形的采样率转换、去噪处理、语音特征提取等。
3. 模型训练
接下来,你需要构建DeepSpeech2模型,并进行训练。这里,我们可以使用deepspeech.pytorch这个开源项目。首先,克隆项目:
```bash
git clone https://github.com/SeanNaren/deepspeech.pytorch.git
cd deepspeech.pytorch
修改train.py中的参数,包括训练集、验证集和生字表。这里,你需要将`train-manifest`、`val-manifest`和`labels-path`三个参数修改为你的数据集路径。
4. 模型测试
训练完成后,你可以使用测试集来评估模型的性能。这里,我们可以使用deepspeech.pytorch提供的Model类来加载和测试模型。
```python
from deepspeech import Model
加载模型
model = Model(\output/model.s2t\)
model.enableExternalScorer(\output/score_model.scorer\)
测试模型
with open(\test_data/test.wav\, \rb\) as f:
audio = f.read()
text = model.stt(audio)
print(text)
5. 模型部署
你可以将训练好的模型部署到你的应用程序中,实现语音识别功能。
三、:DeepSpeech2的无限可能
通过以上步骤,你就可以使用DeepSpeech2进行语音识别了。当然,这只是冰山一角。在实际应用中,DeepSpeech2还有许多其他功能,比如实时语音识别、语音合成等。
DeepSpeech2的强大之处在于,它不仅能够识别标准的普通话,还能识别各种方言和口音。这使得它在语音助手、自动字幕生成、智能客服等领域有着广泛的应用前景。
DeepSpeech2是一个功能强大的深度语音识别系统。通过学习它的应用代码,我们可以更好地了解其原理,并将其应用到实际项目中。相信在不久的将来,DeepSpeech2将会带给我们更多的惊喜!





 QQ客服
QQ客服